3,000년 인간의 역사를 순식간에 학습하는 에이지 오브 울트론

작년에 개봉한 어벤저스에서도 인간을 지배하려는 인공지능을 보유한 로봇이 등장한다. 헬크인 배너와 같이 완성한 울트론은 스스로 인간의 역사를 순식간에 학습하고 결국을 지구를 지키기 위해 인간멸종이라는 판단을 하게 된다. 이처럼 딥러닝은 대량의 데이터를 기계가 스스로 빠르게 분석 및 학습하며 인간과 같은 사고까지 가능한 인공지능 기술이다.
사람의 두뇌 뉴런(신경세포) 구조를 담고 있는 딥러닝(Deep Learning)
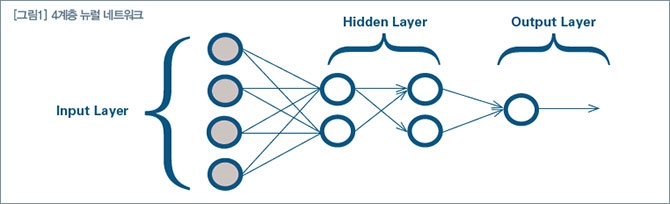
두뇌는 대략 천억 개의 뉴런과 그 접속 부위인 시냅스로 서로 얽혀 있다. 이러한 뉴런은 다른 뉴런들과 복잡하게 연결되어 있으면서 끊임없이 정보를 주고받는다. 사람의 두뇌는 경험 및 학습을 통해 새로운 시냅스가 형성되고 이것이 반복되면 뉴런(신경세포)은 점점 강화되는데, 이러한 뉴런의 구조를 그대로 컴퓨터에 담고 있는 것이 바로 딥러닝이다. 딥러닝은 [그림1]의 뉴럴네트워크 다층 구조 기반으로, 해당 Input layer에 정보가 입력되면 다계층의 Hidden layer에 전달되며 해당 전달과정에서 어떤 가중치를 갖고 다음 단계의 Hidden layer에 다시 전달된다. Hidden layer는 여러 개의 입력된 정보에 의해 또 다른 가중치를 가지며 이러한 단계를 거쳐 최종 Output layer에서는 추론된 결과를 제시할 수 있다.
예를 들어, ‘3’이라는 손 글씨를 컴퓨터가 인식하기 위해서 과거에는 ‘3’의 이미지와 유사한 패턴을 모두 입력해주어 인식하였다. 하지만, 딥러닝에서는 첫 번째 계층에서 ‘3’의 숫자와 관련된 몇 개의 패턴과 생성한 후 두 번째 계층을 거치면서 수천수만 개의 패턴을 스스로 추론하며 구성할 수 있다. 딥러닝은 이러한 과정을 기반으로 다양한 형태의 손 글씨 숫자를 보다 정확하게 인식할 수 있다.
그럼, 딥러닝(Deep Learnin)은 새로운 신기술인가?
딥러닝은 과거의 인공신경망 기술을 기반으로 한 알고리즘과 동일하다. 다만, 과거의 인공신경망 이론은 많은 데이터 속에서 패턴을 발견하는 것이 필수였으나 그만큼의 데이터 량을 확보하기가 어려웠고, 설령 데이터를 확보하여도 수천 수만 개의 복잡한 뉴럴네트워크를 처리할 만큼의 컴퓨팅 처리 능력 확보도 어려웠다.하지만, 최근에는 IoT Internet of Things 에 의한 대량의 센서데이터, 포털/SNS를 통해 실시간으로 생성되는 빅데이터에 의해 필요한 데이터를 손쉽게 확보 가능하며, GPU병렬 컴퓨팅 기술의 등장으로 기존의 슈퍼컴퓨터와 유사한 빠른 처리능력 저렴한 가격으로도 확보할 수가 있다. 오늘날 딥러닝이 유망한 기술로 많은 부각되고 있는 이유도 이러한 기술 발전에 기인하고 있으며, 그 발전과 더불어 다양한 분야에서도 많은 효과가 제시되고 있다.

우측사진 출처) http://cs.stanford.edu/people/karpathy/deepimagesent/
딥러닝(Deep Learning) 기술의 활용분야
딥러닝은 간단한 사고를 요구하는 이미지 인식 등의 분야에서 대량의 데이터를 기반으로 복잡한 사고를 요구하는 예측 또는 판단하는 분야까지 활용될 수 있다. 간단한 사고를 요구하는 사례로, 구글의 딥페이스는 이용자의 얼굴을 어떤 각도에서 보더라도 파악해내는 서비스를 제공하고 있으며 사람의 사고와 같은 수준의 높은 정확성을 갖추었다는 평가를 받고 있다. 좌측 이미지는 스탠포드의 한 연구로 블랙셔츠를 입은 남자가 기타를 치고 있다는 이미지의 행동까지 유추하고 있다. 컴퓨터에 적용된 딥러닝은 이러한 복잡한 사고까지 가능하게 하고 있다.
복잡한 사고를 요구하는 또 다른 사례로는 자율 주행 드론 및 자동차 분야를 예로 들 수 있으며, 다양한 도로 상황을 실시간으로 판단하여 안전하게 차량을 운전하도록 지원하기도 한다. 최근에는 은행거래 시의 범죄행위(갑작스런 고액이체 등)로 추정될 수 있는 이상 현상도 이러한 딥러닝을 활용하여 컴퓨터에 의해 실시간으로 판단할 수 있다. 이런 분야 외에도 빅데이터 분석을 통한 예측, 최적화, 로봇제어 등의 실시간 분석과 판단이 요구되는 곳에 매우 유용하게 적용될 수 있다.
일반적인 기업에서도 딥러닝은 다양하게 활용될 수 있는데, 이러한 딥러닝 도입 시의 어려운 점 중에 하나가 데이터 전문가의 확보이다. 하지만, 딥러닝은 기존의 데이터마이닝, 데이터 고급분석처럼 반드시 많은 전문가를 필요로 하지 않을 것으로 예상된다. 우선, 다양한 클라우드 플랫폼에서 딥러닝을 중요 서비스로 제공하거나, 또는 향후 제공할 예정이다. 그 밖에도 라이브러리 형태, 오픈 API서비스를 통해서도 쉽게 적용할 수 있다. 즉, 기술적인 문제가 중요하기보다는 어떤 비즈니스 문제를 데이터 축적과 활용으로 해결할 지가 중요한 것이다. 마지막으로 딥러닝을 먼 미래의 기술로 보기보다는 서비스를 찾아내고 도메인의 노하우를 축적시키는 방법으로 활용한다면 기업 입장에서의 가시적 성과도 어렵지 않게 확보할 수 있을 것이다. 



















-small.jpg)



